

On the convergence of Adam and beyond
Reddi et al., ICLR 20181Unlike the Adam paper and the AdamW paper, which appeared first on Arxhiv and then at ICLR, as posters, this one appeared at ICLR 2018 first, won Best Paper, and then appeared in 2019 on Arxhiv. As of now, it has just under 2,500 citations.
Summary
The paper is based on an observation that Adam2Adam: A Method for Stochastic Optimization
Kingma and Ba, Arxhiv 2014 doesn’t always converge. The paper claims that the exponential decay of the momentum effectively means that the
gradient updates are relying too much on more recent gradients, and not remembering enough about past updates. In
particular, there may be regular, but infrequent, large gradients, (element-wise,) and that these are averaged out by
the exponential decay of the gradients. The paper argues that they should be taken into account. Since the squared
gradients occur in the denominator of the step size, “taking into account” means taking shorter steps.
To prove this they set up a toy problem that revolves around a MOD 3 setting where the loss is small for every 2 out of 3 iterations, and then large on the third. The true global optimum is dominated by the large term that occurs every third step, and so an algorithm that is optimal for this problem will ignore every first and second. Yet, Adam “forgets” about this condition and ends up choosing the pessimal solution, which happens to be locally optimal for the two small gradients. In practice this suggests that the occasional rare large gradient element should not be ignored. It does make sense that one cannot learn how to learn from hard cases by learning how to learn from easy cases.
If you come across AMSGRAD, (not to be confused with AdaGrad,) then this is the paper that introduced it.
Algorithm
The paper’s solution is simply to take a max magnitude over all window-averaged squared gradients ever observed, and divide each gradient update by that.

In the regular Adam algorithm, \(\hat{v}_t\) is defined as \(\hat{v}_t = v_t / (1 - \beta_2^t)\)3Our Adam paper review discusses this in detail.. The term that it divides by is a normalization factor that ensures \(\hat{v}_t\) is an unbiased estimate of the squared gradient. The AMSGrad algorithm dispenses with this, and it also dispenses with the same bias correction for the momentum term – there is no \(\hat{m}_t\) here, while there is one in Adam.
The last step is a bit tricky – the vector \(\hat{v}_t\) is promoted to a diagonal matrix \(\hat{V}_t\), and then it is used as a projection matrix for projecting onto the “feasible set”4In some settings e.g., Support Vector Machines there is a feasible set, but for deep neural networks the feasible set is usually the whole of \({\mathbb R}^d\).. If \(x_t - \alpha_tm_t/\sqrt{\hat{v}_t}\) is in the feasible set, then there is no need to pay any attention to the \(\Pi_{\cal F, \sqrt{\hat{v}_t}}()\) part, and we can instead think of the last stem as, \[ x_{t+1} = x_x - \alpha_tm_t / \sqrt{\hat{v_t}}, \] which is the same as in Adam, except for using \(m_t\) instead of \(\hat{m_t}\). At any rate, taking a max over \(\hat{v}\) over the entire training run means that the largest element of \(\hat{v}\) will never decay away, and that’s what the paper means by “long term memory”.
Analysis
As mentioned above, the paper considers a generalized setting where the average quadratic gradient term \(\hat{v}_t\) expands out to a matrix \(V_t\). The paper immediately restricts \(V_t\) back to being diagonal, because there are very few settings where a non-diagonal \(V_t\) is practical to optimize5The paper’s generalized framework also allows for the loss function to be different at each step, though they are almost certainly thinking of the effect of evaluating under different batches, not literally changing the loss function.. The paper’s analysis concludes that convergence requires the difference between successive quadratic terms to be Positive SemiDefinite (PSD), i.e. \(V_{t+1} \succ V_t\). For diagonal matrices, this means they have to be elementwise positive, which is the same as having, \(\hat{v}_{t+1} \ge \hat{v_t}\). In the paper’s generalized framework, the condition can be stated as, \[ \Gamma_{t+1} = \left( \frac{\sqrt{V_{t+1}}}{\alpha_{t+1}} - \frac{\sqrt{V_t}}{\alpha_t} \right). \]
In other words, this means that the step normalization term in the numerator is always growing faster than the learning rate is decreasing in the denominator.
As in Kinga & Ba, the paper proves a couple of complicated learning regret bounds, and in fact they have very similar forms. Compare Theorem 4 from this paper,
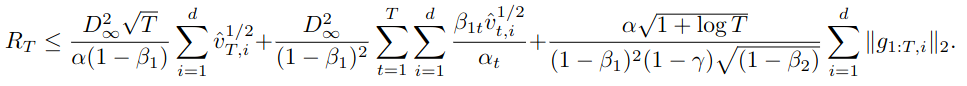
with this regret bound from the Kingma and Ba paper6See our Adam paper review for an explanation of the terms such as \(G_\infty\) etc.:
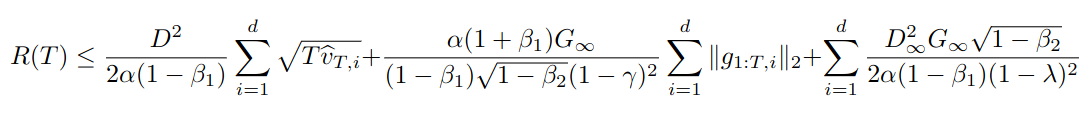
At any rate, the paper claims that it’s bound is considerably better than the \({\cal O}(\sqrt{dT})\) of standard SGD.
Experiments
The first experiment is a deep dive into the toy problem from the Analysis section, and sure enough AMSGrad destroys Adam. The paper also shows some experiments on CIFAR and MNIST and sure enough it’s a little better than Adam. More specifically, it tends to decrease its loss function even faster than Adam, and in the CIFAR10 plots it looks like it does get to a lower loss value, though it’s a bit hard to tell.
My observations
The positive difference condition the paper talks about is a sufficient condition for convergence; there are constructive examples where its violation leads to badness, but it doesn’t otherwise appear to be necessary. That is, it could be that Adam converges most of the time because this condition is met anyway, without taking any extra steps to ensure that it is, but Adam probably would converge in at least some cases even if it is not.
Indeed, while AMSGrad is a highly useful addition to the toolkit, it has not displaced Adam as the dominant way of
optimizing models. Take for instance the GPT3 paper7Language Models are Few-Shot Learners
Brown et al., NeurIPS 2020
– it doesn’t make any use of AMSGrad, and while it uses an interestingly non-default \(\beta_2\) value of \(0.95\), it
does use the Kingma & Ba default value for \(\epsilon = 10^{-8}\). That’s notable because this paper claims that,
One might wonder if adding a small constant [\(\epsilon\)] in the denominator of the update helps in circumventing this problem… The algorithm in (Kingma & Ba, 2015) uses such an update in practice, although their analysis does not. In practice, selection of the \(\epsilon\) parameter appears to be critical for the performance of the algorithm.
In other words, they are claiming that the \(\epsilon\) parameter is silently correcting for a deficiency in the Adam algorithm, but I don’t see any evidence of careful tuning of \(\epsilon\) like this passage suggests.
But for me the real takeaway is that, given how Adam often gives a (slightly) less accurate model than SGD, and that early stopping seems to be a good way of adjusting for this, are we really sure it’s a good idea to fix Adam so that it converges even better?
Thanks for reading to the end!
Comments
Comments can be left on twitter, mastodon, as well as below, so have at it.
New post!
— The Weary Travelers blog (@wearyTravlrsBlg) September 10, 2023
Paper outline: The AMSGrad paper, "On the convergence of Adam and beyond"https://t.co/9ZrnYZY7xZ
Reply here if you have comments.
To view the Giscus comment thread, enable Giscus and GitHub’s JavaScript or navigate to the specific discussion on Github.
Footnotes:
Unlike the Adam paper and the AdamW paper, which appeared first on Arxhiv and then at ICLR, as posters, this one appeared at ICLR 2018 first, won Best Paper, and then appeared in 2019 on Arxhiv. As of now, it has just under 2,500 citations.
Adam: A Method for Stochastic Optimization
Kingma and Ba, Arxhiv 2014
Our Adam paper review discusses this in detail.
In some settings e.g., Support Vector Machines there is a feasible set, but for deep neural networks the feasible set is usually the whole of \({\mathbb R}^d\).
The paper’s generalized framework also allows for the loss function to be different at each step, though they are almost certainly thinking of the effect of evaluating under different batches, not literally changing the loss function.
See our Adam paper review for an explanation of the terms such as \(G_\infty\) etc.
Language Models are Few-Shot Learners
Brown et al., NeurIPS 2020