

Attention is all you need
Attention is all you need
Vaswani et al., NeurIPS 20171As of writing this review, the paper has just over \(94,000\) cites. There is no Arxiv version of this paper.
This is the paper that started the LLM revolution, and it’s also changed the face of ImageNet-style visual object categorization problems as well as anything that can be modeled as sets of sequences. Another lasting impact is that it put a stake in the heart of recurrence as a general problem solver2That is, at least without there being a direct need for it., by reifying what recurrence abstracts – position encodings and the long-range interactions themselves. The notable contribution is the Transformer unit, which is built around an Attention mechanism – everything else in the Transformer is essentially input and output plumbing for it.
Interestingly, the idea for Attention predates the paper. Rather, as the title suggests, the paper proposes that building large models around that mechanism alone is sufficient for some rather impressive results. Arguably, almost everything that the LLM revolution has produced since this paper is simply a result of scaling up this idea. Whatever the next Big Idea is, it has to be something not found here, and I wouldn’t hold my breath.
Let’s dig in!
Summary
The paper opens by essentially declaring Recurrence as a dead end because while it is expressive, it makes models harder to train efficiently. That was a rather bold position to take at a time when LSTM and GRU models were still dominating the landscape. The famously ebullient essay The Unreasonable Effectiveness of Recurrent Neural Networks was itself only two and a half years old at the time3As of writing, this paper itself is almost six years old..
The paper also disposes with Convolutions, which was also bold. On the one hand, Convolutional units really found their ideal application with image processing tasks, but on the other, when the object of interest is sequences, Convolutions deserve at least some consideration of their advantages.
Instead, the model proposes a new way of using Attention to model long-range interactions between items in a sequence, hence the catchy name4A Google Scholar search for papers with “all you need” since 2017 produced \(47,800\) results..
Attention
Recurrent models are based on the idea that each state at time \(t\) should be a function of the previous \(t-1\), but for interesting problems, the information needed at time \(t\) might have been in a state several time steps ago. The simplest solution is to put all of the information into the current state, so that each state is a kind of global representation of all previous states. But, that is hard.
The Attention idea is to let each state at time \(t\) be related to just that time \(t\), and maybe some of its recent neighbors. Now, instead of using only state \(t\) to predict \(t+1\), we use some collection of previous states. The members of that collection are expressed by the Attention vector: a weighted average over past states indicating how much “attention” should be paid to them, hence the name. The how of populating the Attention vector is the business of the Transformer unit.
The paper credits several papers5Neural machine translation by jointly learning to align and translate
Bahdanau et al., Arxiv 2014
Neural machine translation in linear time
Kalchbrenner et al., Arxiv 2016
A decomposable attention model for natural language inference
Parikh et al., Arxiv 2016
Jakob Uszkoreit is an author of this paper, (Parikh et al.,) as well as the Transformers paper itself. for having proposed or developed the idea of Attention. The idea of self- Attention is where the Attention vector is
specifically aimed at past states of a sequence, as opposed to other sequences, and the paper cites three more papers6Long short-term memory-networks for machine reading
Cheng et al., Arxiv 2016
This one proposes a memory architecture add-on to LSTM networks, which the Transformers paper cites as a form of
self-Attention.
A structured self-attentive sentence embedding
Lin et al., Arxiv 2017
This one introduces the term “self-attention”, and also proposes it as an add-on to LSTM networks.
A deep reinforced model for abstractive summarization
Paulus et al., Arxiv 2017
This one uses the term “intra-attention”, and adds it on to an encoder-decoder network, based on LSTMs.
for that. Clearly this is an idea with some history, and it suggests that people were well aware of how the un-rolled
training of recurrent networks was a juicy target for optimization.
The Transformer architecture
This paper is about a new type of unit, so it spends a fair amount of its space talking about how to put the pieces together.
Multi-Head Self-Attention
Now that we’re defining Attention at a finer level, we have to introduce three concepts: queries, keys, and
values. Each of these is a kind of embedding, with dimension \(d_k\), \(d_k\) and \(d_v\) respectively. If you want to
understand what’s going on inside of a Transformer, you should get used to seeing a lot of Qs, Ks, and Vs.
As mentioned before, the Attention unit outputs a linear combination of states – the values, meaning that
clearly the weights are the Attention vector we spoke of before.
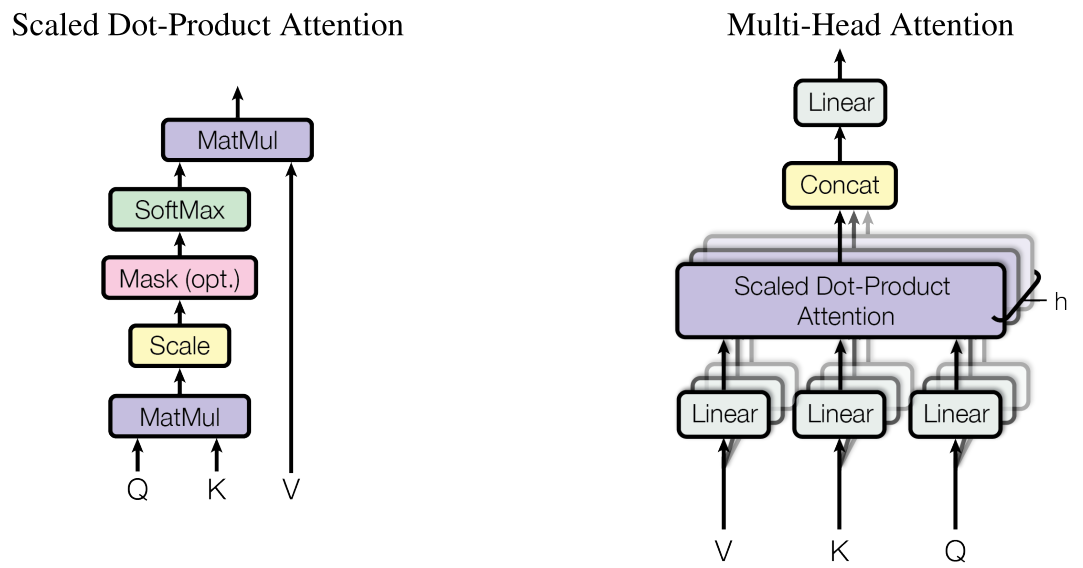
So how does it compute the Attention vector? Each element of the Attention vector is an affinity between a key
and a value. What kind of affinity exactly, is up to the one designing the Attention unit, i.e., there are options.
The paper proposes a simple way to measure affinity – compute linear similarity (i.e. dot product,) divide by
\(\sqrt{d_k}\) and apply a SoftMax to normalize the scale, hence the name, Scaled Dot Product. To do this simultaneously
on all of the tokens in a sequence, the embeddings are all assembled into matrices, so now the dot product is a MatMul,
and so on. A final MatMul applies the weights produced by the Attention vector with the values, and voila – a new
output vector for each token.
But wait a minute, where did these three different embeddings come from? Whenever there’s no logical distinction between
them, the Attention unit just learns its own three separate mappings from the one input vector to queries, keys and
values . As we’ll see below, this is what the Encoders and Decoders built out of Attention Units do when they receive
inputs from only one source. Using one input to derive all three embeddings is what the paper means by “Self”
Attention.
This makes it seem like there’s no real semantic distinction between queries and keys, at least in the context of
pure Self-Attention, and in some sense, there isn’t. There are just two learned sub-encodings that, when they have high
similarity for a token, indicate that the value for that token should be used in making the output. But, as we will
see in a moment, Transformers don’t just use Self-Attention, so there are cases where the distinction matters.
Ok, so what’s this about multiple “Heads”? The idea here is to split the value embeddings into \(h\) smaller embedding
spaces, where the action of query, key and value is replicated for each one. The results are concatenated
back into one long output of size \(d_{model}\) – the common embedding dimension of inputs and outputs. The query and
key embeddings have to have the same dimension as each other, \(d_k\), but it can be whatever you want. The value
embeddings, however, have to be \(d_{model} / h\) so they can concatenate properly. This is shown on the right side of the
figure above.
The paper claims this lets each Head attend to different parts of the inputs in a way that would be “averaged out” with one Head. Given the nonlinearity of SoftMax, this makes a certain amount of sense.
Encoder and Decoder
The Encoder and Decoder both use Residual connections and Layer normalization to wrap Multi-Head Self-Attention units. Both also use a simple MLP (also with layer normalization) to map the outputs into yet another representation. The major difference is that the Encoder has one Attention unit, and the Decoder has two. Why? Because the Encoder is only looking at all of the past inputs to form it’s current input, whereas the Decoder is not only looking over all past inputs (as well,) it’s also looking over all past outputs for clues. Since it’s looking at outputs, it has to be masked so that it doesn’t look into the future. Since the Encoder is not masked, it can use the entire sequence as a kind of scratch pad.
In order to think about Transformers, we have to remember that they receive all of the inputs at once, and when training they receive all of the outputs at once as well. The masking in the output decoder blocks out an upper triangle of the Attention matrix to prevent information from flowing non-causally, so that even though it sees all of the words in each sentence at once, it’s as if it’s seeing them one at a time.
Something that the Architecture diagram shows, (reproduced below,) that the text doesn’t mention until much later, is
that there is one Attention unit where queries come from one place, and keys and values come from another. It’s
in the Decoder’s non-masked Attention unit. The paper doesn’t say much about this, other than to cite a few previous
Attention papers.
Effectively what’s happening is, the “Decoder” has its own Masked encoder that builds a representation of the output
sequence up to a certain token. That representation becomes the key and value. Meanwhile, the “Encoder”’s
representation of the whole input produces the query, whose affinity for the key will determine the attention
given to the value.
Confused yet? The point is that this is why queries and keys have different semantics.
Positional Embeddings
Without Recurrence, the model has to have some way of representing the difference between seeing a particular word at the beginning, middle or end of a sentence. RNNs do this implicitly by adding all of the context into the embeddings as they go, but Transformers do it explicitly by way of a hand-engineered feature vector that encodes only the position information for each word or token. In this paper, they used sine and cosine functions. That is, the position encoding vector’s elements form a sine wave whose frequency increases with the position being encoded, so words towards the beginning of the sentence would have position embeddings that look like slow sine or cosine waves, and words towards the end would have faster and faster waves.
This constitutes one of the extremely rare examples of hand-engineered features in a Deep neural net. This isn’t because such an embedding can’t also be learned. On the contrary, the paper points out that they tried both the learned position embeddings as well the sine / cosine embeddings, and while they both worked about as well, they expect the sine / cosine embeddings would generalize better beyond sequence lengths that have ever been seen.
How are the position embeddings combined with the other embeddings? They’re added. Remember, the goal of Transformers is for vector operations, especially vector addition, to encode semantic relationships.
Model architecture
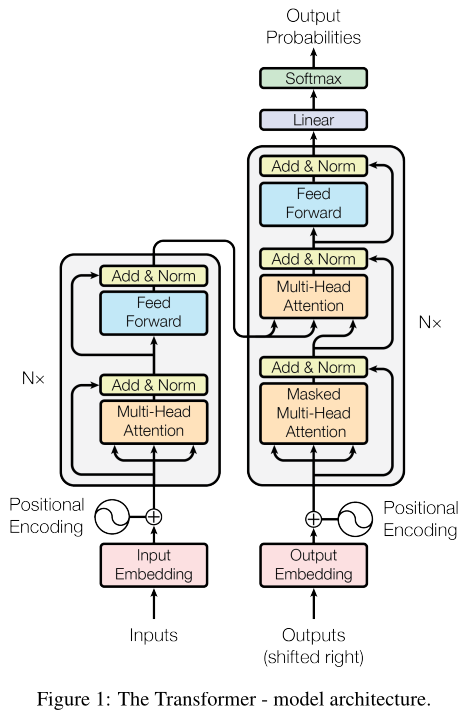
Using the Transformer unit described above, the sequence-to-sequence model is built by “stacking” \(N=6\) separate Transformers. What does “stack” mean? The paper flatly refuses to elaborate, and IMHO this detracts from the paper’s readability7This is one of the rare occasions where I express a value judgment during the Summary, rather than waiting for the end, and it’s because I am annoyed.. The short answer is that “stacking” Transformers is like stacking Linear or Convolutional layers, as opposed to adding or concatenating or linearly combining them, etc. – inputs become outputs as the model gets Deeper, even as inputs also become outputs inside of the Self-Attention unit. Stacking means that in a Transformer, as in “Deep” LSTM architectures, information moves in two different directions. That is, information moves “Depth-wise”, with more encodings in the stack, and it also moves “Causally” from earlier word tokens to later ones.
This may seem like an obvious thing from a modern perspective, but remember that in this blog we try to look at things
as they were at the time. For instance this paper8Sequence Labelling in Structured Domains with Hierarchical Recurrent Neural Networks
Fernandez et al., IJCAI 2007 from 2007 needed separate labels for each layer, and it wasn’t until 2013 that this paper9Speech recognition with deep recurrent neural networks
Graves et al., ICASSP 2013
Graves is an author of the 2007 paper above. outright proposed the idea of stacking LSTMs to make them “Deep”, as the main contribution of the paper, and even
broke another SOTA barrier in the process. Clearly, in the years between 2013 and 2017, this idea became obvious enough
not to warrant a mention of the idea, nor any of the numerical difficulties that went with it.
At any rate, the full Sequence-to-Sequence model is shown in the figure. First, word tokens are mapped to learned embedding vectors, and the position embeddings are added. Then they are fed into the Stacked Transformers to produce the desired embeddings. Finally, a simple classification or regression layer produces the desired outputs.
Experiments
Being a Sequence-to-Sequence model, it was trained on Machine Translation tasks. The inputs come from one language,
and the outputs from another. Why should it be causally masked in this case? That is, machine translation can be done
off-line, so there’s no need to prevent later output tokens from influencing earlier output tokens. It’s probably
because without that Causal information bottleneck10Cf. the Tishby Information Bottleneck paper:
The information bottleneck method
Tishby et al., Arxiv 2000, the model may not have been forced to learn word relations, and instead it has to mimic the way human speakers emit
sentences.
The model was trained with Adam, using a default \(\beta_1\) and a \(\beta_2=0.98\), slightly lower than the default of \(0.99\). The paper used a warmup learning rate schedule, in which the learning rate was gradually raised. The paper doesn’t cite any others for this, but it is surely one of the earlier ones because it has to explain what a warmup learning rate schedule is.
On Machine Translation tasks, the score has BLEU units, where higher is better. For the English-German task, it had the highest BLEU, but on the English-French task, a Convolutional ensemble had the highest BLEU, and another Recurrent ensemble also had higher BLEU. But, they are ensembles and this one is not. Its training cost in FLOPs was also lower by about \(3\times\), according to their estimates of the FLOP budgets of other papers.
They also reported some architecture exploration search, on the smaller German-English dataset. They learned that you can’t shrink the key dimension \(d_k\) too much, that many heads is better than one, but not too many, that bigger models are better, that Dropout helps, and that you don’t need to learn the position embeddings. Based on those insights, they made a Big model, which is the one that got their best results.
So that’s the paper. What did I take away from it?
- This paper is a lot like the AlexNet paper in that it pulled all of its widgets and concepts from previous papers, (even the position encodings!) It appears that the idea of Multi-Headed Attention is the chief novel innovation of this paper, and who knows, maybe that was the only thing holding back all of what followed. Its real contribution was to put them together, (which can be tricky on its own,) and show that this exact combination of things finally lacks all of the bad ideas that had plagued all of the methods that came before it.
- The Transformer idea that makes LLMs such as GPT-4, Claude and others so effective does so because it allows vector
embeddings to encode semantic relations by way of vector operations. This idea isn’t new. In fact, the so-called
word2vecidea11Efficient Estimation of Word Representations in Vector Space
Mikolov et al., Arxiv 2013
Linguistic Regularities in Continuous Space Word Representations
Mikolov et al., NAACL-HLT 2013 from 2013 was really the one that showed that this could be a good idea. That was the one where they just trained a set of word embeddings, in a self-supervised way12Meaning that they train it to predict some part of a text document given only some part of the rest of the document., where the most exciting thing prior was the Web 1T 5-gram dataset. Whenword2veccame out, they showed that their embeddings could replicate semantic relationships by vector addition. For instance, taking \(\mbox{vec}(\mbox{King}) - \mbox{vec}(\mbox{Man}) + \mbox{vec}(\mbox{Woman})\) gave a vector surprisingly close to \(\mbox{vec}(\mbox{Queen})\). As far as I’m concerned, that was the point where the power of this idea was first demonstrated. - As it happens, Transformers are really learning a position-dependent, concentrated dependence of one variable on a set of others. Convolutions also learn a position-dependent, sparse dependence of one variable on a set of others, where the sparsity pattern happens to have been pre-computed. Since then, there have indeed been sparse Transformers, so its not inconceivable that Transformers are in some way generalizing what Convolutions can learn, not just replacing them with something else.
- The paper doesn’t discuss inference on novel inputs at all, and it’s not relevant for fully supervised tasks where there are always outputs available. Even though during training it sees all of its outputs at once, it’s not necessarily the case that it can generate outputs all at once, or maybe just not well. At least, that’s not how GPT works…
- I found it notable that this paper makes a point of ascribing equal contribution to all of the authors, not just
the first two or three. Is this just something they do at Google? The paper by Parikh et al.5Neural machine translation by jointly learning to align and translate
Bahdanau et al., Arxiv 2014
Neural machine translation in linear time
Kalchbrenner et al., Arxiv 2016
A decomposable attention model for natural language inference
Parikh et al., Arxiv 2016
Jakob Uszkoreit is an author of this paper, (Parikh et al.,) as well as the Transformers paper itself., cited as an earlier work on Attention, is a Google paper from that time, and shares an author with this paper, Jakob Uszkoreit, yet there is no such sharing of credit. Perhaps it is because some authors were from Google Research, and others were from Google Brain, making it potentially contentious… Or, perhaps it was because the authors had a sense that this was going to be a major breakthrough paper… Or perhaps it was both.
Final thoughts
This paper has a great idea, but to be blunt, it’s not as well written as some others, IMHO. It’s maddeningly vague on some points, and dwells more than necessary on some others. Fortunately, there was a code base, and if you doubt what they’re talking about you can check it out for yourself.
A recent paper13Data Science at the Singularity
David Donoho, Arxiv 2023 argued that the real driver of scientific progress isn’t just massive datasets and massive compute power, it’s the
frictionless ease with which new ideas can be shared, and replicated. If this paper had to live or die by how well
written it was alone, then the world might have missed out on a lot of really big things.
Thanks for reading to the end!
Comments
Comments can be left on twitter, mastodon, as well as below, so have at it.
New post!
— The Weary Travelers blog (@wearyTravlrsBlg) November 6, 2023
Paper review: The Transformers paperhttps://t.co/rldBca8BUh
Reply here if you have comments, or use giscus.
To view the Giscus comment thread, enable Giscus and GitHub’s JavaScript or navigate to the specific discussion on Github.
Footnotes:
As of writing this review, the paper has just over \(94,000\) cites. There is no Arxiv version of this paper.
That is, at least without there being a direct need for it.
As of writing, this paper itself is almost six years old.
A Google Scholar search for papers with “all you need” since 2017 produced \(47,800\) results.
Neural machine translation by jointly learning to align and translate
Bahdanau et al., Arxiv 2014
Neural machine translation in linear time
Kalchbrenner et al., Arxiv 2016
A decomposable attention model for natural language inference
Parikh et al., Arxiv 2016
Jakob Uszkoreit is an author of this paper, (Parikh et al.,) as well as the Transformers paper itself.
Long short-term memory-networks for machine reading
Cheng et al., Arxiv 2016
This one proposes a memory architecture add-on to LSTM networks, which the Transformers paper cites as a form of
self-Attention.
A structured self-attentive sentence embedding
Lin et al., Arxiv 2017
This one introduces the term “self-attention”, and also proposes it as an add-on to LSTM networks.
A deep reinforced model for abstractive summarization
Paulus et al., Arxiv 2017
This one uses the term “intra-attention”, and adds it on to an encoder-decoder network, based on LSTMs.
This is one of the rare occasions where I express a value judgment during the Summary, rather than waiting for the end, and it’s because I am annoyed.
Sequence Labelling in Structured Domains with Hierarchical Recurrent Neural Networks
Fernandez et al., IJCAI 2007
Speech recognition with deep recurrent neural networks
Graves et al., ICASSP 2013
Graves is an author of the 2007 paper above.
Cf. the Tishby Information Bottleneck paper:
The information bottleneck method
Tishby et al., Arxiv 2000
Efficient Estimation of Word Representations in Vector Space
Mikolov et al., Arxiv 2013
Linguistic Regularities in Continuous Space Word Representations
Mikolov et al., NAACL-HLT 2013
Meaning that they train it to predict some part of a text document given only some part of the rest of the document.
Data Science at the Singularity
David Donoho, Arxiv 2023